Algunas veces necesito una maquina virtual para probar aplicaciones antes de
desplegarlas, o para trastear con alguna configuración, este tutorial describe
el método para crearlas más rápido y sencillo que he encontrado.
Instalación
En el huésped en el que se van a alojar las maquinas, son necesarios los siguientes
paquetes:
$ sudo apt-get install ubuntu-virt-server qemu-kvm libvirt-bin ubuntu-vm-builder bridge-utils
desde donde vayas gestionar las maquinas, es recomendable instalar:
$ sudo apt-get install virt-manager
Configuracion de red
El siguiente paso es modificar la configuración de red del anfitrión, yo prefiero
usar bridging de manera que las maquinas virtuales tengan asignadas direcciones
de red validas. El funcionamiento es ingenioso, se crea un switch virtual
usando la tarjeta de red física, al que los huéspedes se conectan como si se
tratara de una conexión real.
Solo es necesario modificar en archivo /etc/network/interfaces, por ejemplo
si este es el archivo original:
#/etc/network/interfaces
auto lo
iface lo inet loopback
auto eth0
iface eth0 inet static
address 192.168.0.42
network 192.168.0.0
netmask 255.255.255.0
broadcast 192.168.0.255
gateway 192.168.0.1
dns-nameserver 80.53.60.25
Debemos convertir el interfaz eth0 en br0 y añadir las opciones:
#/etc/network/interfaces
auto lo
iface lo inet loopback
auto br0
iface br0 inet static
address 192.168.0.42
network 192.168.0.0
netmask 255.255.255.0
broadcast 192.168.0.255
gateway 192.168.0.1
dns-nameserver 80.53.60.25
bridge_ports eth0
bridge_stp off
bridge_fd 0
bridge_maxwait 4
Tras esto reinicia el sistema o el servicio de red.
$ /etc/init.d/networking restart
$ reboot
Configuración del sistema
Añade un usuario al grupo de libvirtd y kvm para que pueda manipulas las maquinas,
sin necesidad de ser root:
$ sudo adduser `id -un` libvirtd
$ sudo adduser `id -un` kvm
Crea un directorio donde almacenar las imágenes KVM, por ejemplo:
$ mkdir /home/kvm-images
$ chown libvirt-qemu:libvirtd /home/kvn-images
Adicionalmente puedes crea un par de claves ssh para el usuario, de forma que
no tengas que introducir la clave cada vez que administras remotamente la máquina.
En este post explico como se hace.
Crear la máquina virtual
Con todo configurado ya estamos listos para crear la máquina con el comando
ubuntu-vm-builder:
$ sudo ubuntu-vm-builder kvm trusty \
--domain servidor \
--hostname kvm1 \
--arch amd64 \
--mem 2048 \
--cpus 1 \
--rootsize 20000 \
--swapsize 2048 \
--destdir /home/kvm-images/kvm2 \
--user secnot \
--pass secreto \
--bridge br0 \
--ip 192.168.0.201 \
--mask 255.255.255.0 \
--net 192.168.0.0 \
--bcast 192.168.0.255 \
--gw 192.168.0.1 \
--dns 80.53.60.25 \
--components main,universe \
--addpkg acpid \
--addpkg openssh-server \
--addpkg linux-image-generic \
--addpkg unattended-upgrades \
--libvirt qemu:///system ;
Aunque todos esos parámetros parecen muy complicados, sólo la primera linea
es necesaria, las demás permiten especificar la configuración para el huésped:
- destdir - Directorio en el que quieres que se cree la imagen.
- domain, hostname - Dominio y nombre de host del huésped.
- arch - Arquitectura de la maquina a instalar.
- mem, cpus - Cuanta memoria y CPUs son asignadas al huésped.
- rootsize, swapsize - Tamaño del disco raíz en MB (por defecto 4000MB),
y de la partición de intercambio.
- user, pass - Nombre de usuario y clave para la primera cuenta de usuario
en el huésped.
- bridge - Indica a que bridge conectar el interfaz de red del huésped.
- ip, mask, bcast, gw, dns - Configuración de red para el huésped.
- mirror, components - Indica al huésped de que repositorio descargar los
paquetes, útil para acelerar la instalacion si tienes copias locales.
- addpkg - Paquetes a instalar en el huesped durante su creación. Algunos
paquetes son imprescindibles, acpid para poder apagar la maquina,
openssh-server para poder conectarse remotamente, y linux-image-generic
para evitar el error "This kernel does not support a non-PAE CPU"
- libvirt - Indica al instalador en que host debe instalar la maquina.
- ssh-key - Añade la clave pública suministrada (ruta absoluta) a la
lista de claves autorizadas del root.
Podemos comprobar que está funcionando correctamente con virsh:
$ virsh list --all
Id Nombre Estado
----------------------------------------------------
1 kvm1 ejecutando
Si no fue arrancado automáticamente, puedes hacerlo a mano con:
$ virsh start kvm1
Se ha iniciado el dominio kvm1
y detenerlo con:
$ virsh shutdown kvm1
El dominio kvm1 está siendo apagado
Gestión remota
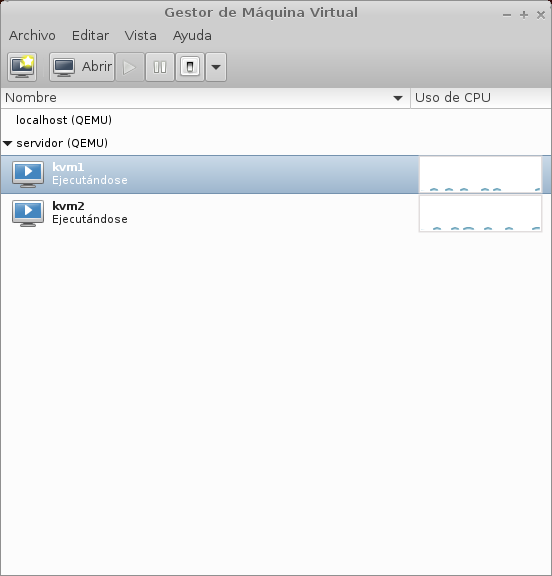
Si además quieres gestionar de forma remota todos los huéspedes KVM, instala virt-manager,
y añade la dirección ip del anfitrión con Archivo>Añadir conexión... usando como
nombre de usuario la cuenta que añadiste a los grupos de kvm. El resultado debería ser
similar a esto:
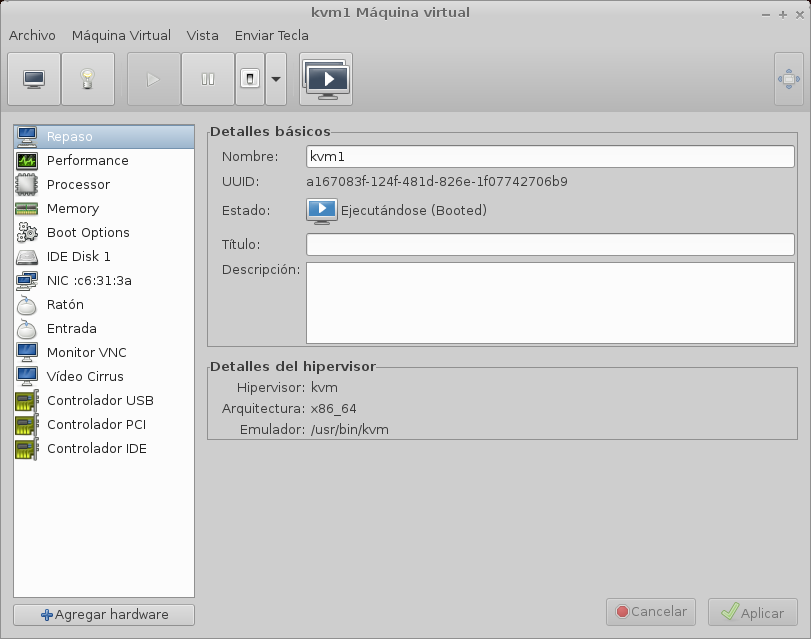
Si haces doble click en cualquiera de las máquinas, puedes abrir una consola, o la
página de detalles de configuración seleccionando vista en la barra de tareas:
Click to read and post comments
A veces es necesario un script shell que se ejecute una sola vez, por ejemplo
cuando estas trabajando en una imagen de una maquina virtual o una distribución,
y necesitas que se ejecute un script la primera vez que arranca el sistema. Estos
scripts son faciles de escribir pero hay que tener cuidado con ciertos detalles
que pueden dar problemas.
La primera aproximación es eliminar el script tras se ejecutado.
#!/bin/bash
# Tus comandos aqui
# Elimina el script antes de salir
rm $0
El problema de éste sistema es que $0 no devuelve la ruta del script sino que
devuelve el nombre usado para su invocación, si se usó ruta absoluta no hay problema,
pero si se usó relativa puede darse el caso que si se ha cambiado el directorio de
trabajo durante su ejecución, no borrara el script o incluso puede borrar un
archivo con el mismo nombre en otro directorio.
La solución es obtener la ruta absoluta del script antes al inicio, y usarla para
borrar el archivo al finalizar.
#!/bin/bash
# Obtener ruta absoluta
RUTA_ABSOLUTA=$(cd `dirname "${BASH_SOURCE[0]}"` && pwd)/`basename "${BASH_SOURCE[0]}"`
# Tus comandos aqui
# Elimina el script
rm $RUTA_ABSOLUTA
Esto es suficiente en la mayoría de los casos, pero en algunas situaciones no es
posible eliminar el script porque puede ser necesario posteriormente. En estos casos
se usa un flag para determinar si el script ya se ha ejecutado.
#!/bin/bash
FLAG="/var/log/archivo-flag.log"
if [ ! -f $FLAG ]; then
echo "Primera ejecucion del script"
# Crear flag para recordar que se ejecuto
touch $FLAG
else
echo "El script solo se puede ejecutar una vez"
exit 0
fi
# Tus comandos aqui
Aquí se ha usado un archivo como flag que es creado en la primera ejecución, cuando
se intenta ejecutar el script posteriormente se detecta la existencia del archivo y
no se continua con la ejecución. Si quisieras ejecutarlo una vez mas, no hay mas que
eliminar el archivo flag.
Este sistema tampoco es perfecto, si por algún error se borra el archivo flag el
script se ejecutaría de nuevo, por lo que hay que tener cuidado con donde y con que
permisos se crea.
Y eso es todo, elige el método que mas te guste.
Click to read and post comments
Comprimir directorios en Linux es imprescindible para muchas tareas de backup y
administración, en éste artículo se muestran dos métodos usando los formatos
tar.gz y zip.
Tar Gzip
El formato mas usado en sistemas Unix/Linux es tar.gz que es un proceso de dos
pasos primero se usa el programa tar para unir todos los archivos a comprimir
en uno solo, sobre el que luego se usa el compresor gzip. Esta secuencia es
tan común que el comando tar incluye una opción para comprimir directamente el
archivo al finalizar.
Puede comprimir un directorio usando:
$ tar -czvf nombre-directorio.tar.gz nombre-directorio
Donde
- -z Comprime el archivo usando gzip
- -c Crea un archivo
- -v Verbose, escribe en pantalla información sobre el proceso de compresión
- -f Nombre del archivo
Imagina que quieres comprimir tu directorio home
$ tar -czvf backup-directorio-usuario.tar.gz /home/usuario
También puedes comprimir todos los archivos dentro de directorio actual
incluidos subdirectorios usando:
$ tar -czvf nombre-backup.tar.gz *
Para restaurar un archivo comprimido:
$ tar -xzvf backup-directorio-usuario.tar.gz
Donde
- -x Indica que debe extraer los archivos
Zip
Algunas veces es necesario que el archivo sea descomprimido en otros sistemas
operativos, en ese caso es útil usar el formato zip que tiene mayor
compatibilidad.
Comprimir varios archivos en un solo zip:
$ zip archivos-comprimidos.zip archivo1 archivo2 archivo3
Comprimir todos los archivos del directorio sin incluir subdirectorios:
Comprimir un directorio completo incluyendo subdirectorios:
$ zip -r directorio-comprimido.zip /home/usuario
Puedes descomprimir archivos zip usando:
Click to read and post comments
Con el auge de los servidores baratos, ya sea VPS o dedicados, cada vez es
mas común que cualquier pequeña página tenga que administrar su propio
servidor, un aspecto que es fácilmente ignorado o incluso olvidado es el
espacio swap, y puede tener una grandes repercusiones en el rendimiento.
¿Que es el espacio swap?
Swap es usado cuando Linux llena toda la memoria RAM física disponible. Si el
sistema tiene swap habilitado, datos almacenados en RAM que no están siendo
usados son movidos a swap temporalmente para liberar espacio. Con esto se
consigue que en momentos puntuales en los que la carga del sistema es alta,
exista espacio extra hasta que pase la congestión.
El espacio swap tiene sus limitaciones, al estar normalmente localizado en
algún medio de almacenamiento masivo, ya sea un disco duro o SSD, tienen
un tiempo de acceso y velocidad de transferencia ordenes de magnitud peores
que la memoria RAM. Por eso un sistema que usa swap de manera continuada
tendrá un mal rendimiento, e indica que no tiene suficiente memoria RAM y
es momento de una ampliación.
Configurar swap en Linux
El primer paso es comprobar si swap ya está activado en el sistema.
$ free -m
total used free shared buffers cached
Mem: 7709 5009 2699 312 55 1198
-/+ buffers/cache: 756 3953
Swap: 0 0 0
Con free podemos ver la memoria disponible en el sistema, en caso de que swap
no esté activado deberá aparecer ceros en la linea de swap.
Si no esta activado el siguiente paso es crear el archivo que se usara como swap
$ sudo dd if=/dev/zero of=/swapfile bs=8G count=4
$ sudo chmod 600 /swapfile
Esto crea un archivo de 8GB (recomendado que su tamaño sea el doble que la RAM),
y cambia los permisos para que no pueda ser leído mas que por el root. Tras esto
hay que crear el espacio swap en el archivo.
$ sudo mkswap /swapfile
Configurando espacio de intercambio versión 1, tamaño = 4194300 kiB
sin etiqueta, UUID=7f2020e5-0a09-4f1b-b0af-3053e94f17e2
Para activar swap
Antes de continuar es recomendable usar free para comprobar que todo ha funcionado correctamente.
$ free -m
total used free shared buffers cached
Mem: 7709 6626 1082 463 189 2464
-/+ buffers/cache: 350 3736
Swap: 7980 1029 6951
Por último es necesario configurar fstab para que swap se active al
arrancar el sistema. Con tu editor favorito añade lo siguiente a fstab.
/swapfile none swap sw 0 0
Y eso es todo, un tutorial MUY básico de como activar swap.
Click to read and post comments
Aviso: Este es un listado de comandos que constantemente olvido y
busco, asi que los he reunido en una lista para tener acceso rápido.
Compresión de directorios
Comprimir:
$ tar -zcvf backup-2013-05-03.tar.gz /home/backup/directory
Descomprimir:
$ tar -zxvf backup-2013-05-03.tar.gz
Vim
Encontrar cada ocurrencia de la cadena 'foo' en el texto, y substituirla por la
cadena 'bar'.
Encontrar cada ocurrencia de la cadena 'foo' en la línea actual, y substituirla
por 'bar'.
Substituir cada ocurrencia de la cadena 'foo' por 'bar', pero pidiendo confirmación
primero.
Grep
Buscar archivos que contengan determinado texto.
$ grep 'nombre' *.txt
$ grep '#include<example.h>' *.c
Debug
Resumen de llamadas al systema realizadas por un comand
$ strace -c ls >/dev/null
Trafico de red excepto ssh
Click to read and post comments
Si estás desarrollando una aplicación web, algún día tendrás que dar el paso
y hacerla pública. Inicialmente puedes usar un servicio como
Heroku pero si tienes éxito, no te quedará mas
remedio que gestionar tus propios servidores o VPS.
Por fortuna desplegar una aplicación django usando nginx y gunicorn, es
más sencillo de lo que podría parecer. En esta pequeña guia trato de describir
el proceso paso a paso:
1 - Crear un usuario para la aplicación django
El primer paso es crear un usuario con el que ejecutar la aplicación
Django, esto nos permite organizar con facilidad un servidor donde estemos
ejecutando varias aplicaciones, proporciona separación de privilegios, y limita
el posible daño que pueda hacerse al sistema si la aplicación es comprometida.
Creamos un grupo al que pertenecerán todos los usuarios de las aplicaciones
django, y un usuario al que le asignamos el nombre de la aplicación.
$ sudo addgroup --system webapps
$ sudo adduser --system --ingroup webapps --home /webapps/appname appname
Al usar en modificador --system, al usuario se le asigna /bin/false como
shell, y no tiene clave, por lo que no puede hacer login. Aunque esto es
una buena medida de seguridad, es muy incomodo mientras se está configurando
el sistema, así que asignamos un shell temporalmente:
$ sudo chsh -s /bin/bash appname
Esto nos permite usar sudo su appname para seguir con la instalación como
el nuevo usuario.
2 - Instalar y configurar virtualenv
Virtualenv es la herramienta que nos permite aislar los paquetes requeridos
por las aplicaciones, de manera que si dos aplicaciones necesitan paquetes
que están en conflicto, no interfieran la una con la otra como ocurriría si
instalásemos todos los paquetes directamente en el sistema.
Instalamos virtualenv con:
$ sudo apt-get install python-virtualenv python-pip
Una vez instalado, hacemos login con el usuario que hemos creado, y dentro de
su directorio usamos virtualenv para generar un nuevo entorno virtual:
$ sudo su appname
$ cd
$ mkdir virtualenvs
$ virtualenv --no-site-packages virtualenvs/app_env
$ source virtualenvs/app_env/bin/activate
Dentro del entorno, hay que instalar todos los paquetes que sean necesarios
para la aplicación, puedes hacerlo uno a uno, o en bloque si tienes el archivo
requirements.txt:
(app_env)$ pip install django
(app_env)$ pip install django-countries
(app_env)$ pip install django-mptt
(app_env)$ ....
(app_env)$ pip install -r requirements.txt
Si quieres profundizar en el funcionamiento de virtualenv sigue este
tutorial
3 - Gunicorn + Supervisor
Gunicorn es el servidor WSGI que se encarga de servir la aplicación, pero
necesita un programa que lo inicie al arranque, y lo monitorice para
reiniciarlo si hay algún problema. La mejor solución es usar el gestor de
procesos como supervisor.
La instalación es sencilla:
$ sudo apt-get install supervisor
Para instalar gunicorn el método más sencillo es hacerlo dentro del entorno
virtual de tu aplicación django.
$ source virtualenvs/app_env/bin/activate
(app_env)$ pip install gunicorn
Una vez todo está instalado, creamos un archivo de configuración para gunicorn
gunicorn_conf.py en el directorio HOME del usuario, en el que indicamos la
dirección y puerto en los que estará escuchando gunicorn:
# gunicorn_conf.py
workers = 3
bind = '127.0.0.1:9000'
A partir de aquí ya podemos salir del entorno virtual de la aplicación:
El siguiente paso es crear el archivo de configuración de supervisor en
/etc/supervisor/conf.d/appname.conf:
[program:appname]
command=/webapps/appname/django_app/run_gunicorn.sh
directory = /webapps/appname/django_app/
user=appname
autostart=true
autorestart=true
priority=991
stopsignal=KILL
Tras esto creamos en el directorio de la aplicación el script
run_gunicorn.sh que etablece el entorno virtualenv para la aplicación y
despuer ejecuta gunicorn:
#!/bin/bash
source /webapp/appname/virtualenvs/app_env/bin/activate
exec /webapp/appname/virtualenvs/app_env/bin/gunicorn -c /webapps/appname/gunicorn_conf.py django_app.wsgi:application
Una vez configurado indicamos a supervisor que debe iniciar el nuevo servicio:
$ sudo supervisorctl start reread
appname: available
$ sudo supervisorctl update
appname: added process group
$ sudo supervisorctl status appname
appname RUNNING pid 21710, uptime 0:00:07
Para detener e iniciar la aplicación podemos usar:
$ sudo supervisorctl stop appname
appname: stopped
$ sudo supervisorctl start appname
appname: started
Llegado a este punto si todo funciona correctamente, ya podemos desactivar
el shell del usuario creado para la aplicación.
$ sudo -s /bin/false appname
Si prefieres que sea posible hacer login con el usuario, es recomendable que
le asignes una clave.
4 - Nginx
Usamos Nginx para hacer de pasarela entre los clientes y gunicorn, y para
servir los archivos estáticos de la aplicación. Para instalarlo:
$ sudo apt-get install nginx
Para configurar nginx, hay que crear un archivo /etc/ngix/sites-available/,
en el especificaremos donde se debe conectar a gunicorn en la sección upstream,
y la ruta a los archivos estáticos de tu aplicación en la sección server:
upstream django_app_server {
# Dirección en la que está escuchando gunicorn
server 127.0.0.1:9000 fail_timeout=0;
}
server {
# listen 80 default deferred; # for Linux
# listen 80 default accept_filter=httpready; # for FreeBSD
listen 80 default;
client_max_body_size 4G;
server_name www.dominio.com;
# ~2 seconds is often enough for most folks to parse HTML/CSS and
# retrieve needed images/icons/frames, connections are cheap in
# nginx so increasing this is generally safe...
keepalive_timeout 5;
# Ruta a tus archivos estaticos.
location /static/ {
alias /webapps/appname/django_app/static/;
autoindex on;
}
location / {
# an HTTP header important enough to have its own Wikipedia entry:
# http://en.wikipedia.org/wiki/X-Forwarded-For
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# enable this if and only if you use HTTPS, this helps Rack
# set the proper protocol for doing redirects:
# proxy_set_header X-Forwarded-Proto https;
# pass the Host: header from the client right along so redirects
# can be set properly within the Rack application
proxy_set_header Host $http_host;
# we don't want nginx trying to do something clever with
# redirects, we set the Host: header above already.
proxy_redirect off;
# set "proxy_buffering off" *only* for Rainbows! when doing
# Comet/long-poll stuff. It's also safe to set if you're
# using only serving fast clients with Unicorn + nginx.
# Otherwise you _want_ nginx to buffer responses to slow
# clients, really.
# proxy_buffering off;
# Try to serve static files from nginx, no point in making an
# *application* server like Unicorn/Rainbows! serve static files.
proxy_pass http://django_app_server;
}
}
Descargar
Una vez configurado, hay que enlazar el archivo que hemos creado en
/etc/nginx/sites-available/ a /etc/nginx/sites-enabled/, de esta manera
nginx empezará a usar la configuración:
$ sudo ln -s /etc/nginx/sites-available/midominio /etc/nginx/sites-enabled/midominio
Por último reiniciamos nginx:
$ sudo service nginx restart
Nota: Los autores de gunicorn tiene un ejemplo más completo de un archivo de
configuración
nginx.conf
Alternativas
Por supuesto esta no es la única opción para desplegar django, ni es la mejor
para todas las situaciones. Si estas administrando múltiples aplicaciones,
y/o múltiples servidores quizás Docker o
Dokku se ajuste mejor a tus necesidades.
Y como comenté al inicio Heroku es una buena
alternativa para páginas con poco tráfico.
Click to read and post comments